
I haven’t been writing enough lately as I’ve spent too much time fumbling through the dark heart of the Internet.
This is not a place I choose to dwell, but instead I get drawn in by random alerts and reminders that propel me to check various online tools, which lead me to problems that suck me down a rabbit hole of lost time and energy.
I’m talking about problems from hackers, scammers and content scrapers, and oh my, they can be time wasters!
My purpose for writing about my most recent episode is not to complain, but to illuminate for the innocent what perils lie in the online world and how you can protect and/or defend your site.
Meet the content scrapers
The episode started a couple of weeks ago when an article about disavowing bad backlinks caught my attention and made me think to check my own site’s backlinks in Webmaster Tools.
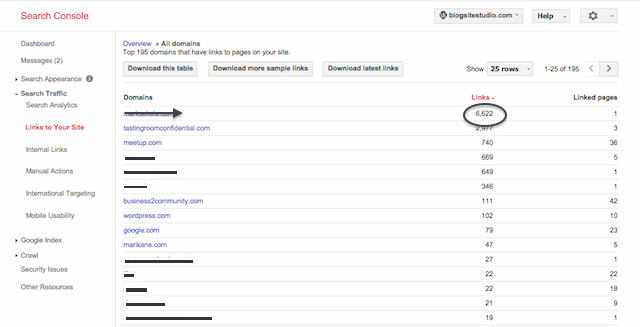
Once there, I noticed that a site I redesigned for a client a couple of years ago had 6600 links pointed to Blogsite Studio! Super suspicious. These links had only been placed two weeks before, so I’m glad I caught it.
Takeaway: Check your data in Webmaster Tools regularly!
Read More: How to Use Webmaster Tools and Make Google your Friend
The links were, you guessed it, porn, which is exactly the type of link Google will penalize your site over. Before I disavowed them, my first course of action was to contact my client, get his logins, and get into his site to kill that “Designed by Blogsite Studio” link in the footer.
To be honest, it’s no wonder my client’s site was hacked. He hadn’t upgraded WordPress and plugins in two years!
Takeaway: Regularly update your WordPress installation and all plugins!
Once I removed the offending link, I set about creating a list of links to send to Google for disavowment.
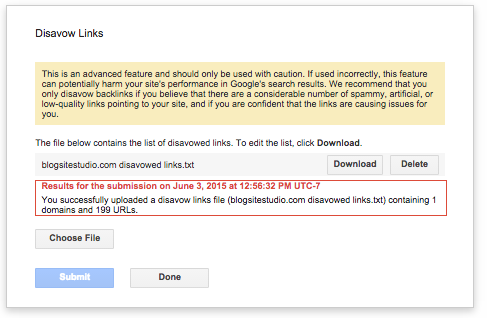
Disavowing comes with warnings not to use lightly and to first try to get the offending webmaster to remove them. Fat chance of that here.
Takeaway: Disavow bad or spammy links to your site!
In the process, I started to investigate some of the other sites that were linked to mine and what I found blew my mind.
There were dozens of sites linking to Blogsite Studio from posts scraped from Blogsite Studio! Actually, these posts were not scraped directly from Blogsite Studio, but from Business2Community.com, with whom I have an agreement to republish my posts via my RSS Feed.
I had heard about content scraping years ago, but never paid much attention to this practice of extracting data from Web pages, which has been around as long as the Internet.
In recent years, content scrapers have come out of the closet and new and better tools for scraping have been developed.
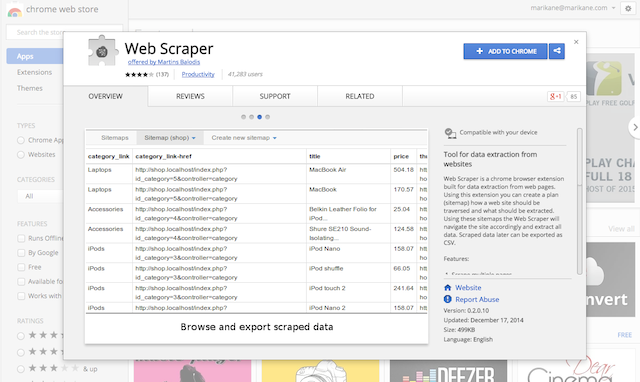 Ironically, Google advises against web scraping while at the same time offering a Chrome app called Web Scraper to make scraping easier! Makes me want to ask, Google, whose side are you on?
Ironically, Google advises against web scraping while at the same time offering a Chrome app called Web Scraper to make scraping easier! Makes me want to ask, Google, whose side are you on?
In my case, entire articles from the past 1.5 years were posted on all kinds of sites in their entirety – links, images and all. Copyright infringement or what?
The editor of B2C assured me that these sites did NOT have permission to republish their web pages and that the problem of scraping is so widespread, they can only go after site owners who do not provide any attribution.
Most of the scraper sites I found did provide attribution to me and to B2C. But the byline and footer were both linked to B2C! The scraper sites I found in Webmaster Tools were there by virtue of the internal links I’d place within the content.
Takeaway: Always place at least one internal link in your content.
So if someone clicks on my byline or the footer, they go to B2C. If they were so intrepid, they might click on my bio there and traffic would go Blogsite Studio, but that’s less likely. My SEO nephew told me this is a process called deep linking and it’s actually better than surface linking, but it still pisses me off.
I work hard to post original, thoughtful stories and here these yahoos are gaining traffic off my posts, scraped through a middleman.
How much traffic I was losing was a question that sent me to Google’s search engine. I entered the full titles of my stories, with quotation marks, and lo and behold found yet more scraping sites ripping off my posts!
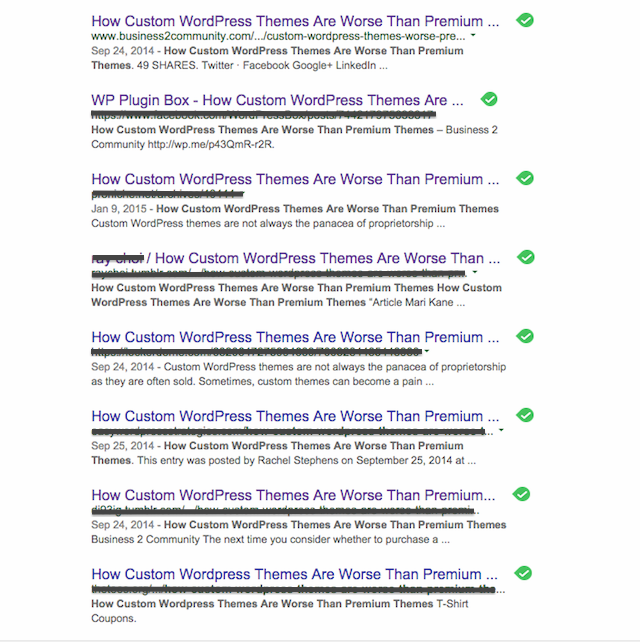 Some of these were not on my Webmaster Tools list since they contained no internal links to connect them to me.
Some of these were not on my Webmaster Tools list since they contained no internal links to connect them to me.
What really got me was the fact that many of these scraper sites ranked higher that even B2C and certainly higher than Blogsite Studio from which the posts originated!
Takeaway: Google your post titles occasionally.
What to do about content scrapers
The sad fact is that content scraping is so widespread and ongoing, cracking down is like playing whack-a-mole with web pages. Nobody wants to do anything because they’re too busy.
In 2014, Google launched a Scraper Report Tool to report sites that get higher ranking than your original posts.
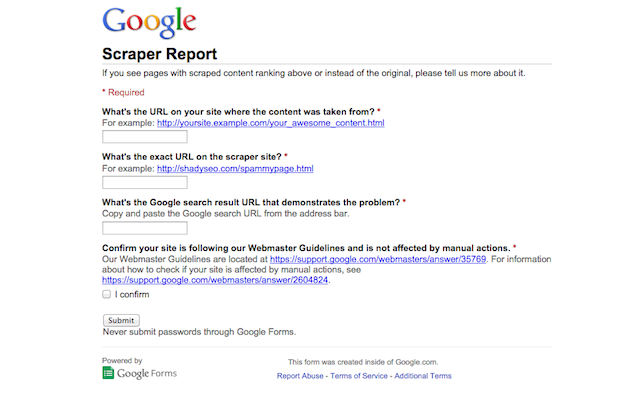
While promising nothing in the way of fixes, the form asks for the original permalink, the content scrapers permalink, and the URL of the Search Engine Results Page (SERP) page showing how the original post is being out ranked.
(And yet, Google offers a tool for scraping content!)
After reading numerous “there’s nothing you can do” posts about content scraping, I decided to do something. I emailed my attorney.
After being presented with all the evidence, my attorney concluded that my copyright was indeed being violated and he crafted a letter for me to send to the offenders.
But first, I thought I’d test the waters by placing a comment on one offending site that did not give me credit, informing this WordPress podcast host what Google says about content scrapers, and asking him to link to my original article. Since his comments were linked to Facebook, my comment inadvertently appeared there.
His response was not apologetic, nor accommodating, but dickish. Instead of linking back to my site, as I asked, he linked to the SERP page for the post title, forcing readers to wade through that.
Looking around his site I found not one original article, and yet his byline topped every Read More page.
Mind you, I am not the only B2C contributor being ripped off by content scrapers. Every site I found has posts from B2C contributors, and with more time to waste I would reach out to these bloggers about it. So if you have contributed to B2C, you might want to investigate content scrapers.
Takeaway: Increased exposure from curated sites means a higher probability of being scraped.
Since then, I’ve slowly sent my attorney’s letter to a handful of the offending sites I bookmarked.
The response has been mixed: from none, to removing the entire page and leaving a 404 error, but not one site owner has apologized in any way.
Bottom dwellers
For some reason, because this is the Internet, people think all content is fair game to steal. Or, share, to put it nicely.
Sharing is one thing I can get behind, but when you take a piece of writing and republish it in its entirety, and misattribute it or take credit for it, guess what? That’s copyright infringement, which is wrong, unethical and karmically dangerous, and there are laws against it.

jettbritnell.com
I’m may be busy, but the fact that “WordPress experts” and “lead generation” sites are ranking higher than my site for my post outrages me to no end. I’m going to continue to send notices and follow up with these offenders.
The really shady sites actually have no contact pages or email addresses. Those will receive DCMA notices, like the one I filed already.
So, in answer to my title question, what’s the difference between a content scraper and an eel?
One is a bottom-dwelling, scum-sucking scavenger and the other is a fish.
How about you? Has your content been scraped? What did you do?
Hi Mari,
Is it possible to have Google remove your content from the offender’s site if you are the original author? I thought that was the purpose of Google Authorship.
Thanks!
Lori
It is possible to get the content removed, but Google won’t do it. I am going to post an update on what to do when you’ve been scraped, shortly. Please stay tuned.
And, Google Authorship is gone, so that’s a dead end.
Thanks1